Pythonでデータ分析する方法を5ステップで初心者向けに解説してみた
日本マイクロソフト株式会社との共同開発講座を受講可能。経済産業省が定めるReスキル、JDLAのE資格の認定講座受けるならキカガク!
【第2位】Aidemy(公式:https://aidemy.net/)
日本の大企業のDXで利用されている、高品質なPythonスクール。給付金で受講料が最大70%OFF。給付金が使えるPython・AI・機械学習特化型スクール。
【第3位】TechAcademy(公式:https://techacademy.jp/)
価格を抑えて、教養としてAI・Pythonを学びたいなら!統計学の基礎からPythonのライブラリ使ってデータ分析の手法を習得できます。知名度抜群の総合型プログラミングスクール。
【第4位】CodeCamp(公式:https://codecamp.jp/)
価格を抑えながらスクレイピングなどPythonでのデータ収集・業務自動化を学びたいなら!同じく知名度抜群の総合型プログラミングスクール。
「Pythonでデータ分析する方法は?何を勉強すればいいの?Pythonでデータ分析するメリットは?」

実際、この記事を読んでいるあなたは、「毎日業務で、一つずつExcelにデータを打ち込んでめんどくさい」「もっと簡単にデータを取ってきて可視化・分析したい!」と考えているのではないでしょうか?
Pythonはデータの収集からモデル化まで一貫して対応しており、初学者でも比較的書きやすいので、「ちょっとビジネスでデータ分析してみたい!」というときに重宝されます。
目次 (PRも含まれます)
Pythonでデータ分析する流れ

データ分析の流れとして、
- 答えを出したい問い、課題の設定
- データの収集
- データの前処理
- データの可視化
- 機械学習の場合、モデル化
となっています。これらの流れは、行ったりきたりします。データの可視化をした結果、データの前処理がさらに必要になったり、モデリングした結果、さらにデータの前処理が必要になる可能性があるからです。
①答えの出したい問い、課題の設定

ある分析を行う際に、どういう結果が得られればいいのか定義します。例えば、
- この二つの広告のうち、どちらがよりクリックされやすいか、商品申し込みまでつながりやすいか
- もっとも商品申し込みに貢献しているWebページはどれなのか
などです。
個人的には、「答えを出すことによってビジネス成果が生まれるもの」を課題として設定するのがよいと思います。
例えば、以下のようなことを検証したとしても、次の行動に落とし込めません。
- NG: 気温が上がると、アイスクリームの売上が伸びるのか →仮にそうだったとしても、気温を上げることができないので意味がない
一方で、最初に挙げた二つのような問いに答えられると、次のアクションの根拠とすることができます。「これが分かったらこのアクションが取れる」という仮説をもとに、課題設定することが重要です。
- OK: この二つの広告のうち、どちらがよりクリックされやすいか、商品申し込みまでつながりやすいか → よりビジネス効果の高い広告を利用することで、より多くの申し込みを得られる
- OK: もっとも商品申し込みに貢献しているWebページはどれなのか→そのページに似たようなページを作成する、そのページに内部リンクを多く流す構造にすることでより多くの申込みを得られる
この辺のリサーチデザインに関して、参考になる書籍をいくつかまとめておきます。リサーチデザインについては、いろいろな事例に触れながら、どういうことができるのかを多く把握しておくことが重要です。
- データ分析の実務プロセス入門(あんちべ):ビジネスの現場におけるリサーチデザインを学ぶために大事です。
- 機械脳の時代――データサイエンスは戦略・組織・仕事をどう変えるのか?(加藤エルテス):ビジネスにおける、データ分析の事例をまとめている本です。
②データの収集

次に、上記の課題を解決するために、データを収集します。データを収集する方法は、おおざっぱに分けると以下のようになっています。
- オープンデータの統計を利用する
- 社内DBのデータを抽出する
- Webスクレイピング、Web APIを利用してデータを収集する
オープンデータの統計を利用する
一番簡単なのは、オープンソースは、公的統計を利用する方法です。オープンデータとは、公的機関などが二次分析のために公開しているデータセットとなります。
個人的に分析しがいがあるオープンデータをまとめておきます。
- PISA: OECD加入諸国が実施している学習到達度調査のデータセットです。
- e-stat:e-Statは、日本の統計が閲覧できる政府統計ポータルサイトです
- Kaggle: データ分析のコンペサイトです。
オープンデータの分析の例としては、教育社会学者の舞田先生の分析が非常に面白いので、ぜひ参考にしてみてください。
また、Kaggleもオープンデータを分析するプラットフォームです。チュートリアルとなっているカーネルを参考にすると、面白いかと思います。英語が読める方はぜひ参考にしてみてください。
社内DBのデータを抽出する
DBのデータを取得する場合は、SQLや、PythonのSQLラッパーを利用してデータを収集することになります。
SQLの基礎は、Progateで学べるのでぜひ勉強してみてください。
Web API、スクレイピングでデータを収集する
外部Webサイト、ツールからデータを取得する場合、Web APIやWebスクレイピングを利用します。
Web APIとは
Web APIとは、アプリケーションが外部連携するためのデータの窓口のことです。例えば、Twitter, Instagramなど以下のようなAPIがあります。
- Twitter REST API
- Instagram Graph API
- Google Search Console API
- Slack APIs
- Chatwork API
- LINE Messaging API
実際にWeb APIからデータを取得できるチュートリアルもManajobのPythonコースで学習できます。
Webスクレイピングとは
Web スクレイピングとは、Web上のHTMLのデータを自動収集できる技術のことです。
Web APIと同様に、以前スクレイピングの方法についてもチュートリアルで作成したので、参考にしてみてください!
③データの前処理

データを収集しても、そのまま利用できるわけではありません。分析の用途に沿った形で、データを加工してあげる必要があります。データの前処理には、以下のようなものがあります。
- 欠損値の取り扱い
- カテゴリカルデータを連続データに変換
欠損値の扱い
例えば、データセットの中で欠損値が存在する場合があります。こういう場合、データ分析を行う際に大きく全体の結果をゆがめる可能性があるので、
- 欠損値をそのまま削除する
- 平均、中央値、最頻値を代入する
- 重回帰分析を利用して、代入する
などの方法をとる場合があります。
Kaggleのタイタニック号の死亡率予測コンペを例にします。乗員客船の搭乗港のカテゴリカルデータ(C, Q, Sの欠損値を、最頻値(mode)で置換しているコードです。ソースコードは下記チュートリアルから引用します。
freq_port = train_df.Embarked.dropna().mode()[0] # 欠損値を削除し、その中で搭乗港コードの最頻値を出力
≫'S'
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port) #欠損値に最頻値を代入
train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)欠損値、最頻値、中央値、平均、仮説検定、p値等の用語がわからない場合は、統計学の基礎を勉強するのがおすすめです。統計学も、機械学習ではなく、純粋な高校数学レベルの統計学ですね。
- マンガでわかる統計学:なんとなく統計学の用語を理解したい人向け
- 教科書だけでは足りない大学入試攻略確率分布と統計的な推測:統計学の基礎をちゃんと学びたい人向け
- Rによるやさしい統計学:Pythonではないけど、大数法則のシミュレーション等をプログラミングで学べたので非常によかったです。
カテゴリカルデータから連続データに変換
カテゴリカルデータ(文字列)を統計解析が可能なように連続データに変換します。
Pythonを利用すると、搭乗港のコードを、定量的なデータに前処理することが簡単にできます。
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()Pythonでデータの前処理をする際におすすめの勉強方法
Pythonでデータの前処理を学ぶ場合は、以下の書籍を参考にするとよいでしょう。
また、Kaggleのカーネルを写経しながら学ぶのもおすすめです。
④データの可視化

Pythonでデータの可視化を行う場合は、以下のモジュールを利用できるようになるとよいでしょう。
- Matplotlib: Pythonで一番メジャーなグラフ描画ツール
- Pandas: データの前処理モジュール。一部Matplotlibの機能が利用できる
- Seaborn: Matplotlibのラッパーライブラリ
個人的にはPythonでグラフ描画をするのは、データの前処理を行う際に簡易的にデータを眺める程度で使うのがいいと思うのですが、レポーティングにはちょっと耐えられないかな…という印象です。ですので、Seabornを利用してきれいなグラフを作るなら、CSVにエクスポートしてBIツールに投げ込んだり、Excelのグラフなどでレポーティングしたほうがいいのではないかな?と思っています。
MatplotlibやSeabornを利用して、グラフ描画を行いたい!という方は、以下の書籍がおすすめです。
⑤機械学習の場合、モデル化

データの前処理が終わり、機械学習やディープラーニングを利用できる状態になったら、最後にモデル化を行います。
前述のタイタニック号の分析の場合は、タイタニック号の生存に寄与した変数を、さまざまな統計モデルを利用して、精度を検証します。例えば、
- ロジスティック回帰分析
- サポートベクターマシン
- 決定木
個人的には、機械学習をビジネスにどう応用するかを学ぶ際には、以下の書籍が非常にわかりやすかったです。
あと機械学習で良かったのは、TJO先生(@TJO_datasci )の著書で、実際のビジネスユースケースをもとにRで機械学習を学べる『手を動かしながら学ぶビジネスに活かすデータマイニング』という書籍。こんなに削ぎ落としてエッセンスを説明してくれるスキル純粋にすごいと思った。https://t.co/txtWBPoHdY
— DAI (@never_be_a_pm) August 16, 2018
Pythonでデータ分析するメリット

Pythonでデータ分析するメリットは以下の点となります。
- データの収集→前処理→可視化→モデル化までに対応している
- 大規模データ(csv1000行以上)のデータの前処理がしやすい
- 初学者にも比較的書きやすい
エクセルだけで完結させようとすると、データの収集がかなりしんどいです。VBAでもできなくはないのですが、ちょっと重いかもしれません。また、前処理もエクセルだけで利用しようとすると、関数だらけになりめちゃくちゃ重くなります。また、かゆいところに手が届かないですね。
また、ほかのプログラミング言語(特にR)と比較すると、初学者でもかなり理解しやすいので、ちょっとビジネスでデータ分析してみたい!くらいのレベル感であれば、Pythonはおすすめできます。
Pythonでデータ分析するデメリット

Pythonでデータ分析するデメリットは、以下2点です。
- Pythonを覚える学習コストが大きい
- グラフのレポーティングがつらい
やはり、簡単なデータのグラフ化や、ピボットテーブルを利用して統計解析したいくらいのレベル感であれば、Google SpreadSheetやExcelを利用した方が早いです。コードを書かずにポチポチするだけで簡単にできるので、それくらいのことであればPythonをゼロから勉強する学習コストのほうが大きくなってしまいます。
また、最終的なレポーティングに利用するようなグラフは、Pythonだとちょっとしんどいかなっというのが印象です。CSV出力した後に、だいたいExcelでレポーティングしているのですが、レポーティングをPythonで凝ってつくるのは費用対効果がかなり悪いと個人的には思います。
CSV1000行未満で、データの収集もしないで、簡単なレポーティングをしたいぐらいの集計作業であれば、Pythonは向かないので、むしろExcelを使えるようになったほうがよいかと思っています。Excelで簡単なデータ分析を行う方法は、こちらの本がかなりわかりやすかったのでおすすめです。
Pythonでデータ分析すべきシチュエーション
メリット・デメリットから考えて、Pythonを利用したほうがよいケースとしては、
- 1000行以上のcsvでデータの前処理をvlockupなどの関数を多用しないといけない。そうすると重すぎて作業できない
- Web API、スクレイピングなどを通して、データの収集から分析までノンストップでやりたい場合
こんな場合はPythonがパワフルかと思っています。
一方で
- データ行数が1000行以内
- プログラミングの学習コストがでかい
などを考えると、ExcelやGoogle Spreadsheetで十分なのではないかと思います。
未経験からPythonでのデータ分析を仕事にできる?

なぜかというと、これらの職種は、普通のエンジニアと違って、プログラミングの技術+統計学や微積や線形代数などの数学の素養・機械学習の知識などが求められるので、かなり難易度が高いんですよ。
具体的には、一から勉強するとなると、
- 学ぶことが多いので、自分で学習ステップを立てていくのが困難
- 専門性が高いので、プロからのFBなしでは、かなり理解するのが難しい
以上のようになり、相当ハード、というかほぼ無理ゲーなんですね。
こういったデータサイエンティストや機械学習エンジニアとかの類は、まずサーバーサイドエンジニアになってから、そこから勉強して転職というパターンがほとんどです。
将来的にデータサイエンスや機械学習の領域に転職したり、業務で活かしたい場合
ただ、「将来的にデータサイエンスや機械学習の領域に転職したい!」「マーケターの業務でプログラミングを習得・スキルアップして市場価値を高めたい!」という場合であれば可能です。
前述した通り、通常、データ分析領域は学習するのが難しい分野ですが、スクールに通うことで以下のメリットがあり、学習しやすくなります。
- 体系的にPythonに特化してプログラミングから数学や統計学の知識を学ぶこと可能
- 現役のデータサイエンティストや機械学習エンジニアに質問できたり、フィードバックがもらえる
- スクールだからこそ、業界に詳しいカウンセラーやエンジニアの方とキャリアについて相談できる
実際に、Aidemyというスクールを受講され、以下のようにキャリアアップされたケースがあります。
- もともとコールセンターでマネージャーとして5年間の業務経験
- その後AidemyでPythonやデータ収集・処理、機械学習を学習
- 社内転職後、AIプロジェクトでデータの生成や学習を管理するマネージャーとしてキャリアアップ
Pythonでデータ分析を始めるにも、まずは何を分析できるようになりたいのか?どんなキャリアを目指すのか?目標を決めて情報収集してから学習を始めるのが大切です。
相談することで、無駄に情報収集に時間を割かなくて済みますし、その分他のことに時間を有効活用できますよ。
Pythonが本格的に学べるおすすめのスクール
ここからは、DAINOTEが実際に取材・体験しておすすめできるPythonのスクールについて紹介しておきますね。
- キカガク(公式:https://www.kikagaku.ai/campaign/)
日本マイクロソフト株式会社との共同開発講座を受講可能。経済産業省が定めるReスキル、JDLAのE資格の認定講座受けるならキカガク! - Aidemy(公式:https://aidemy.net/)
日本の大企業のDXで利用されている、高品質なPythonスクール。給付金で受講料が最大70%OFF。給付金が使えるPython・AI・機械学習特化型スクール。 - TechAcademy(公式:https://techacademy.jp/)
価格を抑えて、教養としてAI・Pythonを学びたいなら!統計学の基礎からPythonのライブラリ使ってデータ分析の手法を習得できます。ビジネスマンにおすすめ! - CodeCamp(公式:https://codecamp.jp/)
価格を抑えながらスクレイピングなどPythonでのデータ収集・業務自動化を学びたいなら!こちらもビジネスマンにおすすめ!
キカガク
キカガク公式: キカガクは、給付金をもらってお得に学習しながらAI人材を目指すことができる、完全オンラインのプログラミングスクールです。 引用:キカガク公式 キカガクの講座は、Udemyでも高い評価を得ており、1つのコースで35,000人以上が受講している講座もあります。 実際、受講した方の生の声を見てみても、非常にポジティブなものばかりでした。(受講された方のレビューはこちらから) ※また、キカガクは一度スクールに申し込むと、全ての講座を無期限で受講することができるのでかなりお得です。 キカガクでは、無料体験を申し込むだけでUdemy上で高い評価を得たコースを実際に体験することができます。 受講できるコースは以下の2つで、合計20時間分の学習動画無料になります。 整理すると、キカガクは以下の方におすすめです。 ※キカガクの講座の無料体験は、3分ほどですぐに学習を始めることができます。

https://www.kikagaku.ai/
コースの特徴
オンライン動画学習サービス、Udemyでも絶賛された高品質の学習コンテンツ
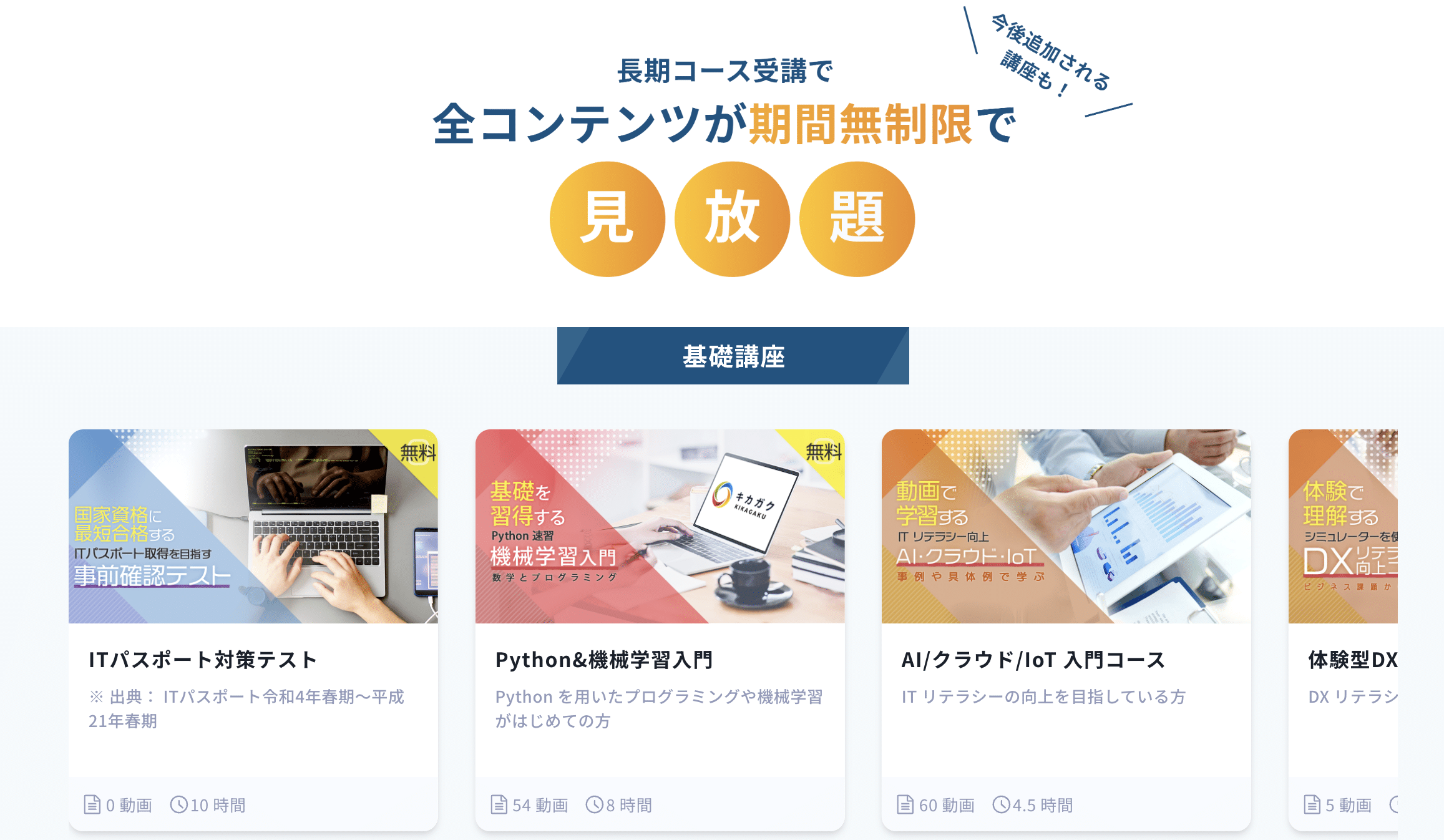
実際の講座を受講前に体験することができる
Aidemy
Aidemy(公式):https://premium.aidemy.net/
Aidemyは、AIに特化した東大発のプログラミングスクールです。 東証一部上場企業のAI研修などもおこなっている、日本最大級のAI教育サービスを提供しています。 AIを本格的に学べるプログラミングスクールの中でも、非常にハイレベルで高品質のスクールです。 Aidemyでは、Pythonに特化した講座を8種類用意しています。 各コースの金額は以下の通りです。 引用:https://premium.aidemy.net/(2023年4月時点。金額はすべて税込価格です) また、雇用保険の支給要件を満たしている方であれば、以下4つの講座で教育訓練給付制度(専門実践教育訓練)を利用できます。 対象者であれば、実際に支払った受講料のうち最大70%を支給してもらえる制度です。 Aidemyでは挫折しにくいサポートに加え、一部の講座では残りの受講期間を有意義に使える学び放題システムを利用することもできます。 丁寧なサポートを受けつつ、AIに特化した講座を受けたい方が学びやすいスクールです。 国の給付金を利用すれば安く受講できるので、興味のある方は対象者かどうか一度確認してみましょう。

3ヶ月
6ヶ月
9ヶ月
AIアプリ開発講座
¥528,000
¥858,000
¥1,078,000
データ分析講座
¥528,000
¥858,000
¥1,078,000
自然言語処理講座
¥528,000
¥858,000
¥1,078,000
実践データサイエンス講座
¥528,000
¥858,000
¥1,078,000
E資格対策講座
¥327,800
–
–
機械学習マスター講座
¥528,000
¥858,000
¥1,078,000
ビジネスAI対策講座
¥330,000
–
–
組織を変えるDX講座
¥330,000
–
–

TechAcademy
2023年4月時点, TechAcademy公式サイトより TechAcademyは完全オンラインのプログラミングスクールです。 専任のエンジニアがマンツーマンでメンターとしてサポートしてくれます。 TechAcademyでAIを学べるコースとしては があります。 AIコースは、Python x AIを専門に学びたい人におすすめです。 具体的には、 などを、Pythonのライブラリで実装していきます。 一方で、データサイエンスコースは、Python x 統計学を学びたい人におすすめです。 より本格的に などを行っていきます。 30秒ほどで無料体験に申し込むと、 という特典があるので、まずは公式サイトから無料体験を受講してみるのがおすすめです! ※更新情報 2022年2月2日時点、TechAcademyでは3つの特別割引プランがあります。
_TechAcademy_テックアカデミー_-2.png)

AIコースとデータサイエンスコースのポイント

AIコース
データサイエンスコース
学習内容
Python
機械学習
ディープラーニング
クラスタリングプログラミング
機械学習
数学・統計学
モデルの構築
価格/受講期間
174,900円 / 1カ月
229,900円 / 2カ月174,900円 / 1カ月
229,900円 / 2カ月
公式ページ
https://techacademy.jp/course/ai
https://techacademy.jp/course/datascience
無料体験はこちら
①『先割』受講料5%OFF:対象プランに先行申し込みで適応
②『トモ割』10,000円割引:同僚や友人が一緒に受講される場合に適応
(別々のコースになっても割引は適用されます)
③ 『複数コースセット割引』:複数コースをセットで申し込むと、別々に学ぶよりも最大138,000円もお得に。
CodeCamp
CodeCamp公式サイトより:https://codecamp.jp CodeCamp(コードキャンプ)は、完全オンライン・マンツーマンレッスン型のプログラミングスクールです。 中でも「データの抽出や整理を学びたい」という人におすすめなのが「Pythonデータサイエンスコース」です。 Pythonが活躍するデータサイエンスの世界には、 の3つのフェーズがあります。 データサイエンスコースでは、その中でも「データ収集」フェーズに重きをおいた学習内容となっています。 PythonのWebスクレイピングテクニックを使ってWeb上から必要なデータを抽出し、Excelやcsvの形に整理するというような、実務で役立つスキルを会得できるでしょう。 このスキルを会得すれば、面倒な単純作業をPythonにやらせることができるようになります。 気になる人は、無料体験レッスンで内容を体験してみてください。 DAINOTE記事経由でCodeCampの無料オンラインカウンセリングを受けるだけ! ※1万円OFFクーポンなどの他キャンペーンとの併用不可
データサイエンス領域の「データ収集」を重視したカリキュラム

他の割引キャンペーンよりもお得に受講するチャンスです!
(当クーポン以外の割引キャンペーンとの併用はできません)
カウンセリング完了後のアンケートにクーポンコード694076を入力してください。
※クーポン取得後は7日間の利用期限があります
※アンケートに回答後、割引適用の詳細をメールでお知らせします。実際にメールが届くまでに最大で24時間程度かかることがあります
※アンケート回答後24時間経過してもメールが届かない場合は、迷惑メールBOXを確認してください

| データサイエンスコース | |
| 料金 / 期間 | 受講料金 165,000円(税込) / 2ヶ月 + 入学金 33,000円(税込) |
| 学習内容 | Pythonを利用したデータ収集 |
| 公式 | https://www.lp.codecamp.jp/python |
CodeCamp(公式):https://codecamp.jp
プログラミングを仕事にしたい人向け


