Python | Pandasの使い方 | よく使う前処理、可視化方法をまとめみた
Pythonの前処理ライブラリPandasを利用して、データの前処理を行うことが多いのですが、そこでよく使う処理をまとめます。
目次 (PRも含まれます)
Pandasとは
Pandasは、データの前処理を行うライブラリです。エクセルで行うような、行列を扱うことができます。
- データの入力
- データの並び替え
- データの修正
- CSVのエクスポート
- 簡易的な描画
などができます。
Pandasと併用して利用するライブラリ
Pandasと併用するライブラリは、
- matplotlib: 描画ライブラリ
- seaborn: matplotlibのラッパー。もっとかんたんに描画を行うことができる
という感じです。
Pandasのメリット
個人的に、データの前処理はこういう場合はExcelかGoogle Spreadsheetを使います。
- データ量が少ない
- 外部サービスとのデータの連携が必要ない
- 複数のデータセットを扱う必要がない
一方で、Pandasを利用する場合は、
- データ量が多い
- 外部サービスとのデータの連携が多い
- 複数のデータセットを扱う必要がある
という場合には、非常に重宝します。
ライブラリのインポート
Pandasをインストールしていなければ、以下のコマンドでインストールして下さい。
pip install pandasして下さい。
データのインポート
データセットをインポートします。
CSVインポートする
CSVファイルを、Pandasを利用してインポートします。
import pandas as pd
df = pd.read_csv("あなたのCSV名.csv", index_col=0)- CSV名を設定します。
- dfはデータフレームの略。
- index_col=0は、インデックスの列名。0を指定すると、最初の列がインデックスとなります。ないと、Unnamed:0 という列が自動で付与されます。
BigQueryからインポートする
Google Big Queryからデータをインポートします。
import pandas as pd
sql = """SELECT nameFROM `bigquery-public-data.usa_names.usa_1910_current`WHERE state = 'TX'LIMIT 100"""
project_id = 'your-project-id'
df = pandas.read_gbq(sql, project_id=project_id, dialect='standard')- SQLを記述します
- BigQueryのプロジェクトIDを入れます
- dialect:standardにするとスタンダードSQLが利用できます。
データフレームを結合する
データを眺める
先頭行をみる
データの中身を確認するため、最初の行を確認します。
df.head(50) #最初の50個を取得- 引数には行数が入る
- 先頭行が見れる head
- 最終行からn番目を見たい場合は tailを使う
最終行をみる
データの最終行を確認します。
df.tail(30)- 引数には行数を入れる
要約統計量を出力する
要約統計量を出力します。
df.describe()- count: データセットの個数
- mean: データセットの平均値
- min: データセットの最小値
- max: データセットの最大値
- std: 標準偏差
- 25%: 第一分位点
- 50%: 第二分位点
- 75%: 第三分位点
変数の個数を確認する
df.info()
列名を取得する
df.columns列名の型を取得する
df.dtypes
データフレームを結合する
複数のデータフレームがある場合に結合します。df1とdf2を組み合わせて、df3を出力します。
df1 = pd.read_csv("df1.csv")
df2 = pd.read_csv("df2.csv")
df3 = pd.concat([df1, df2])参考)http://sinhrks.hatenablog.com/entry/2015/01/28/073327
データをソートする
列名を指定して、昇順、降順に並び替える
df.sort_values(by=["bookmarks"], ascending=False)- byでは、列名を指定します。
- asending=Falseで昇順、Trueで降順になります。
データを抽出する
列名から、条件を指定して取得します。
列名から、以上、以下を指定して取得する
df[df["列名"] > 20] # 列名の値が20以上の値のみ返します df[df["列名"] < 20] # 20以下の値のみ返しますdf[df["列名"] > 20][df["列名"] <30] # 20以上30未満の値を返します
特定の行の値のものを検索する
ある列から、”2017″が含まれるキーワードを抽出します。
df[df["date"].str.contains("2017", na=False)]- 列名dataで、2017という値が含まれているデータを返します
データをランダムにサンプリングする
APIの利用制限等で、データの取得が限定される時は、ランダムにサンプリングする
df.sample(n=100)- n:サンプリングする数
GROUP BY
df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
データを消去する
del df['col']
df.drop(['col'], axis = 1)- どちらでもできるが、列”col”を削除します。
列名を並び替える
A, B, C, D, Eという列があると仮定します。
df = df[['A', 'B', 'C','D','E']] #列を指定した列で並び替えるデータをコピーする(バックアップ用)
df2 = df.copy()列名を変更する
事前に、
- クエリ数
- クリック数
- 表示回数
- CTR
- 掲載順位
というカラムがあるとします。
列名を後から変更します。
#クエリ数 クリック数 表示回数 CTR 掲載順位
df = df.rename(columns={'クエリ数': 'query', 'クリック数':'clicks','表示回数':'apparence',"掲載順位":"ranks"})CSVに書き込む
CSVファイルにデータを書き込みます。
df.to_csv("csv名.csv")データのクリーニング
置換を行う
変更したい文字と、変換後の文字でデータを置換します。
列の値に制限して置換したい場合
df['列名'] = df2['列名'].str.replace('変更したい文字', '変更後の文字') #特定の列の一文字を置き換えるデータフレーム全体を置換したい場合
df.replace('変更したい文字', '変更後の文字') 正規表現で置換する
正規表現を利用した置換を行う
df.列名.str.extract('(.+)@', expand=True) # @よりも前を検索df["age"]= df.列名.str.extract('(\d\d)さい', expand=True) # 「さい」の前の整数値2つを取得した列ageを追加 df.loc[df.iloc[:,0].str.contains(r'(Hel|Just)')]df.loc[df.列名1 <= 4, '新規列名'] = True # 列名1の値が4未満なら、新規列名にTrueの値をだす
全角・半角文字の変換
日本語文字列を扱っているデータの中に数値が全角で入っている場合がある。これをそのまま集計に入れるとエラーが起こるので、データを変換する。
japandasをインストールする。
pip install japandasあとは普通にpandasをインポートしてあげて、実行する
import japandas as jpd
df.列名.str.h2z() # 全角から半角に変換する
参考)https://japandas.readthedocs.io/en/latest/jpstrings.html
正規表現についてはこちらの記事を参照。
>初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」
もしくは
pip install jaconvして、
# 全角の数値を半角に変換する関数
def normalize(s):
import numpy as np
s = str(s)
if s == "nan":
return np.nan
s = jaconv.hira2kata(s)
s = jaconv.z2h(s)
s = float(s)
return s
df['新しい列名'] = df.全角数値が入っている列名.apply(normalize)してあげると良い。
データ型を数値リテラルに変換する
統計処理を行う際、文字列(String)だと動作しない場合があるので、数値列(numeric)に変換します。
df['列名'] = pd.to_numeric(df['列名']) 列名の、指定した文字から先を削除する
単位を揃えるときによく利用します。
- str.split: 「万」という文字よりも前と後に分け、リストで返します
- [0]でリストの最初の方を取ります
df["列名"] = df["列名"].str.split("万").str[0]特定の文字列を含んでいた時に、Trueなら1, Falseなら0に変換
カテゴリカルデータを0-1に変換する場合に利用する。ただし、数値として扱われるので、クロス集計をする場合はカテゴリカルデータに変換する必要もある。
df["新しい列名"] = df.列名.str.contains("^[0-9]", regex=True) * 1 # 0-9の数値が含まれていたら
df["新しい列名"] = df.列名.isnull() * 1 # NaNの数値が含まれていたら0
df[(df['列名1'].str.contains('文字列1')) & (df['列名1'].str.contains('文字列2'))] # 列名1に文字列1と文字列2が含まれたら特定の数字以上なら●●
df.loc[df.列名1 <= 4, '新規列名'] = 'True' # 列名1の値が4未満なら、新規列名にTrueの値をだす
df.loc[(df.列名1 >= 1) & (df.列名2 < 5), "新規列名"] = 1 # 1-5nの数値なら、なら、1を返す新規列名を作成
経過日数の取得
df["新しい列名"] = pd.to_datetime(df['日付の列']) - pd.to_datetime(df['日付の列2'])
df["新しい列名"] = pd.datetime.today() - pd.to_datetime(df['日付の列1']) # 本日までの経過時間欠損値処理
df.fillna(0) # nanを0に変換するdf.列名.fillna(0) # nanを0に変換する
データに重複があるかチェックする
df.duplicated().any() Seabornを使ってグラフ表示
matplotlibのラッパーであるSeabornを使うと、シャレオツな感じでグラフを描画できます。
- fig.set_size_inches: 画像サイズを変更しおます
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27) #画像サイズを設定する
散布行列を書く
全ての列と列で、散布図を作成します。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
pg = sns.pairplot(df.dropna()) #NaNの削除
pg.fig.title("Correlation Matrix of RTs, Likes, Follower Increase", fontsize=12) #タイトルの設定
pg.fig.suptitle("Outlier in RT and Favs observable", fontsize=12) ヒストグラム
ヒストグラムを書きます。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
sns.distplot(df.列名,kde = True).set_title('タイトル') #列名Seriesを引数に。
plt.show()箱ひげ図
箱ひげ図を書きます。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
sns.boxplot(x=df["列名"])棒グラフ
棒グラフを描きます。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
sns.countplot(x=df["列名"]).set_title("タイトル名")分析処理
Pandasでは、簡単な統計分析を行うことができます。
相関係数を出力する
df.corr()相関係数をヒートマップで可視化する
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
sns.heatmap(df.dropna().corr(), vmax=1, vmin=-1, center=0)
デフォルトのカラーパレットはみにくいので、下記記事を参考に色を設定します。
sns.set_palette("husl")散布図・ヒストグラムを同時出力 (jointplot)
sns.jointplot('列名1', '列名2', data=df)- xlim: x軸の最大値を指定
- ylim: y軸の最大値を指定
- dropna: Trueの場合は欠損値を削除
参考)https://seaborn.pydata.org/generated/seaborn.jointplot.html
クロス集計
df[["列名1", "列名2"]].groupby(['列名1'], as_index=False).mean().sort_values(by='列名2', ascending=False)
Pandasのデータ分析のサンプル
実際に上の処理を参考に、データ分析を行います。
- Pandasのインポート
- データセットのインポート
- データセットの表示
処理の内容は、以下のURLから確認できます。
Pandasのインポート
import pandas as pdデータセットのインポート
今回はCSVがないので、sklearnと言うライブラリから、データをインポートします。
利用するデータセットは、ボストン市の住宅価格を利用します。各変数には、以下のような値が含まれています。
- CRIM 犯罪発生率
- ZN 住居区画の密集度
- INDUS 非小売業の土地割合
- CHAS チャールズ川 (1: 川の周辺, 0: それ以外)
- NOX NOx濃度
- RM 住居の平均部屋数
- AGE 1940年より前に建てられた物件割合
- DIS 5つのボストン市の雇用施設からの重み付き距離
- RAD 大きな道路へのアクセスしやすさ
- TAX $10,000ドルあたりの所得税率
- PTRATIO 教師あたりの生徒数
- B 黒人の比率 1000(Bk – 0.63)^2
- LSTAT 低所得者の割合
データセットの詳細は、以下のURLを参考にしてください。
引用元: ≫ Scikit-learnで機械学習(回帰分析)
早速、データを解析します。
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)データセットの表示
取得したデータセットを表示します。
df.head(10)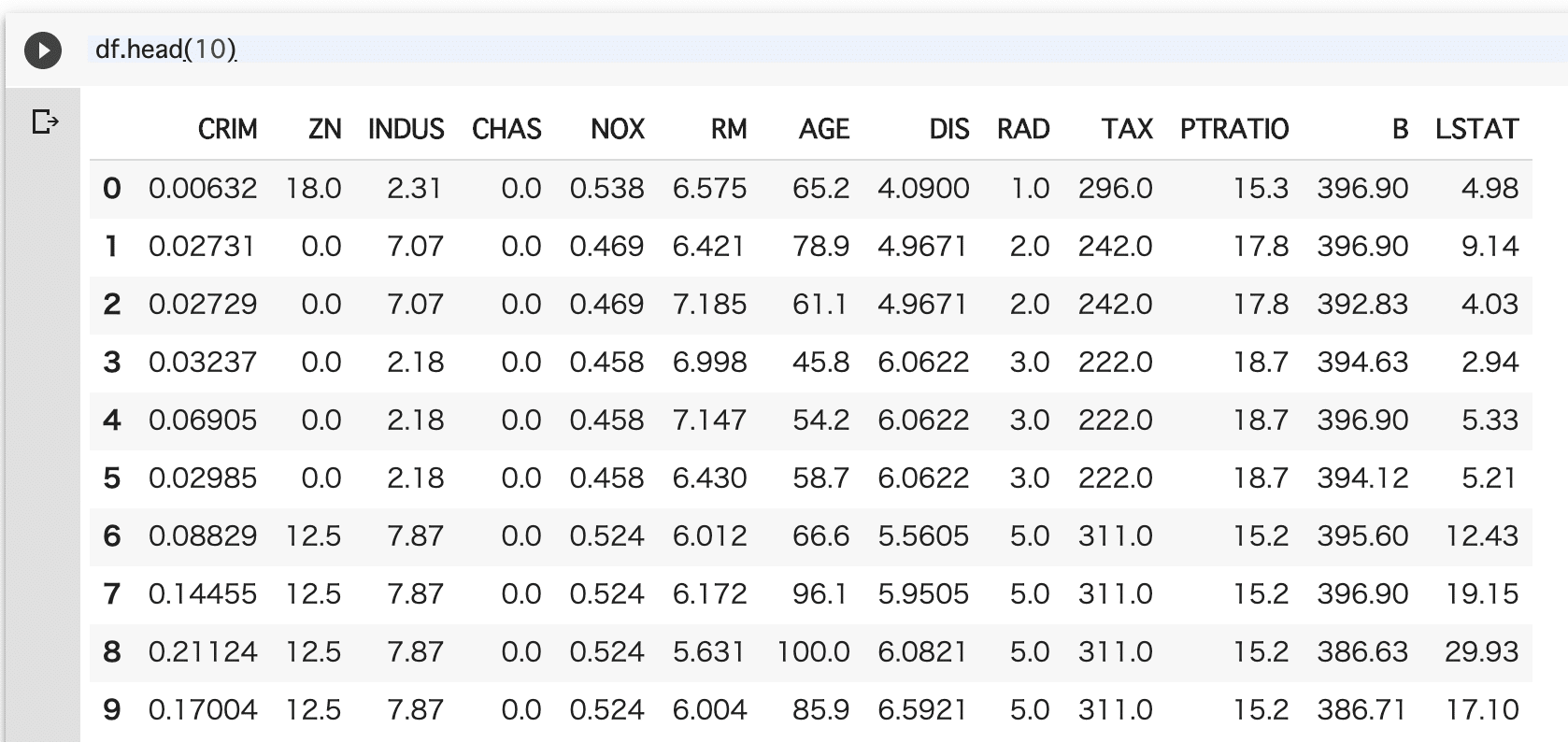
要約統計量の出力
df.describe()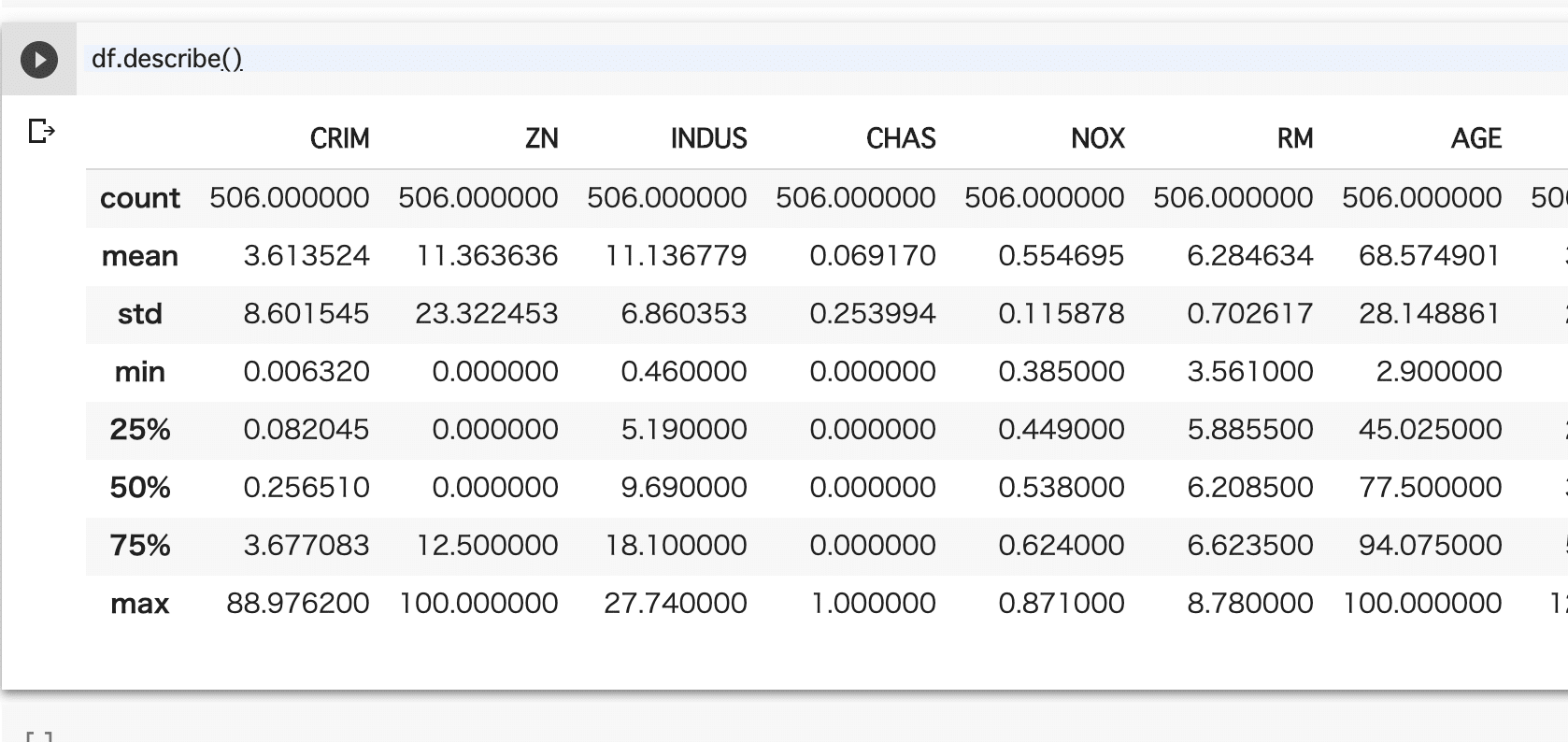
散布行列
データの全体像を把握するために、散布行列を確認します。
本来はもっとまえに前処理が必要なのですが、データセットがすでに綺麗なので省略します。
まずはseabornとmatplotlibをセットアップします。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)散布行列を描きます。
pg = sns.pairplot(df.dropna()) #NaNの削除
こうすると、変数間の関係性を確認することができます。
相関係数の出力
変数間の相関係数を出力します。
df.corr()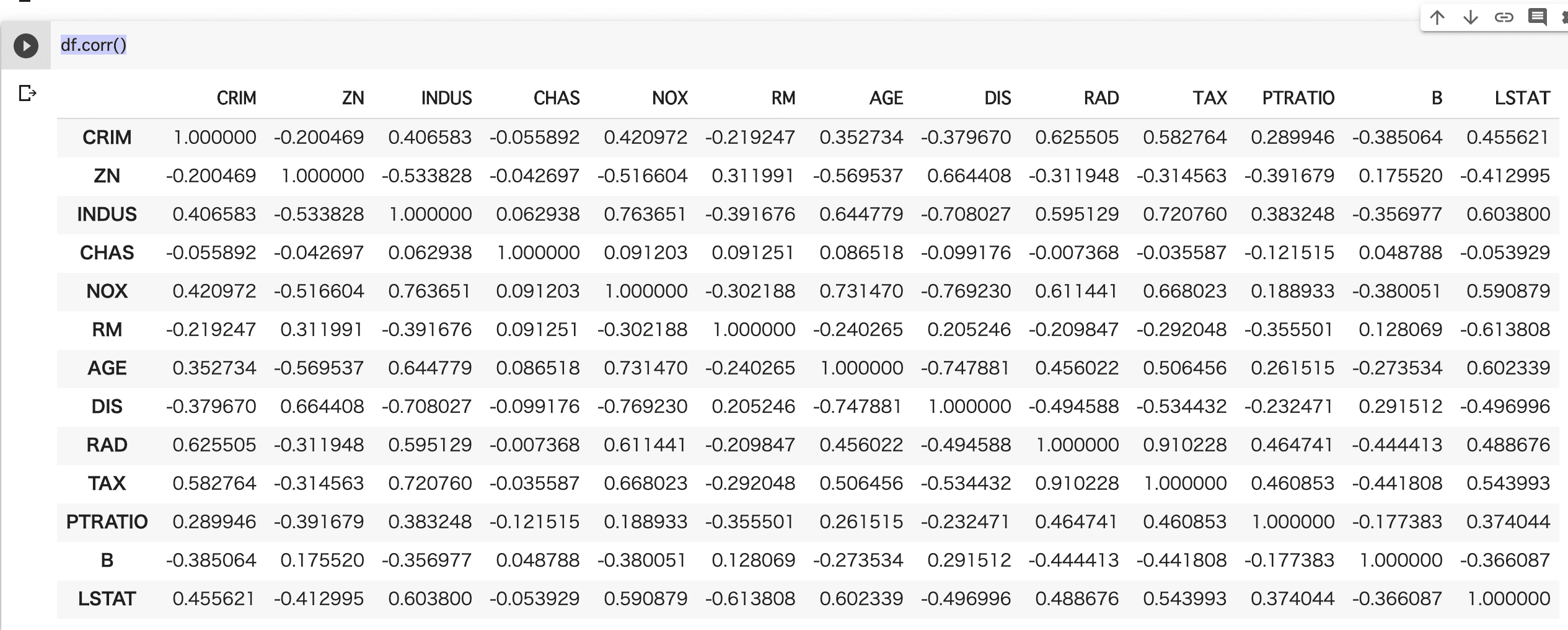
ヒートマップで可視化すると、どこがどう関係しているのかわかりやすいです。
sns.heatmap(df.dropna().corr(), vmax=1, vmin=-1, center=0)
最後に
簡易的ではありますが、Pandasで何ができるのかがわかるかと思います。ぜひ参考にしてみてください!
Pythonを無料で学ぼう! DAINOTE公式チュートリアルを公開しました

- Pythonで簡単なアプリを開発してみたい
- でもまずは無料で勉強してみたい
- ただの基礎ではなく、応用が聴くような技術を身に付けたい
という方向けに、DAINOTE編集部が作成した、Pythonのチュートリアルを用意しました。
まずは、簡単な技術で、プログラミングを楽しんでみませんか?
チュートリアルを見る(無料)

