【スクレイピングツール】面倒な情報収集はGoogle Spreadsheetにやらせよう!
最終更新日:
※追記 2020年3月
DAINOTE編集部で、Pythonによるスクレイピングの方法について、無料チュートリアルを公開しました。未経験の方でもブログからデータを自動抽出できるチュートリアルなので、ぜひ試してみてください!
毎日同じような作業でこのように思っている人はいないでしょうか。
- あ~毎日ネットにアクセスして、同じデータ収集するの面倒くさいなぁ
- こういう退屈な作業、自動でやってくれないかな
- でもプログラミングできないしなぁ。勉強すんのも面倒くさいなぁ。
そんな人に朗報です。今回は、プログラムをかけない人でも、ネットから情報を自動収集する方法をまとめます。
今回使うのは、Google Spreadsheetという、エクセルに似たWeb上のアプリケーションです。実はネット上の情報を自由に取得(スクレイピング)できるツールだとは知られていません。そんな裏の使い方を今回は説明したいと思います。
必要なのは、データを収集したいページのURLとGoogle Spreadsheetだけ
まず、Googleのアカウントを取得して、Google Spreadsheetを開いてください。MicrosoftのExcelとほとんど同じですが、クラウド上で使えるGoogleの純正無料ソフトです。
≫ Excel代わりに使えるGoogleドライブ「スプレッドシート」の使い方活用術!
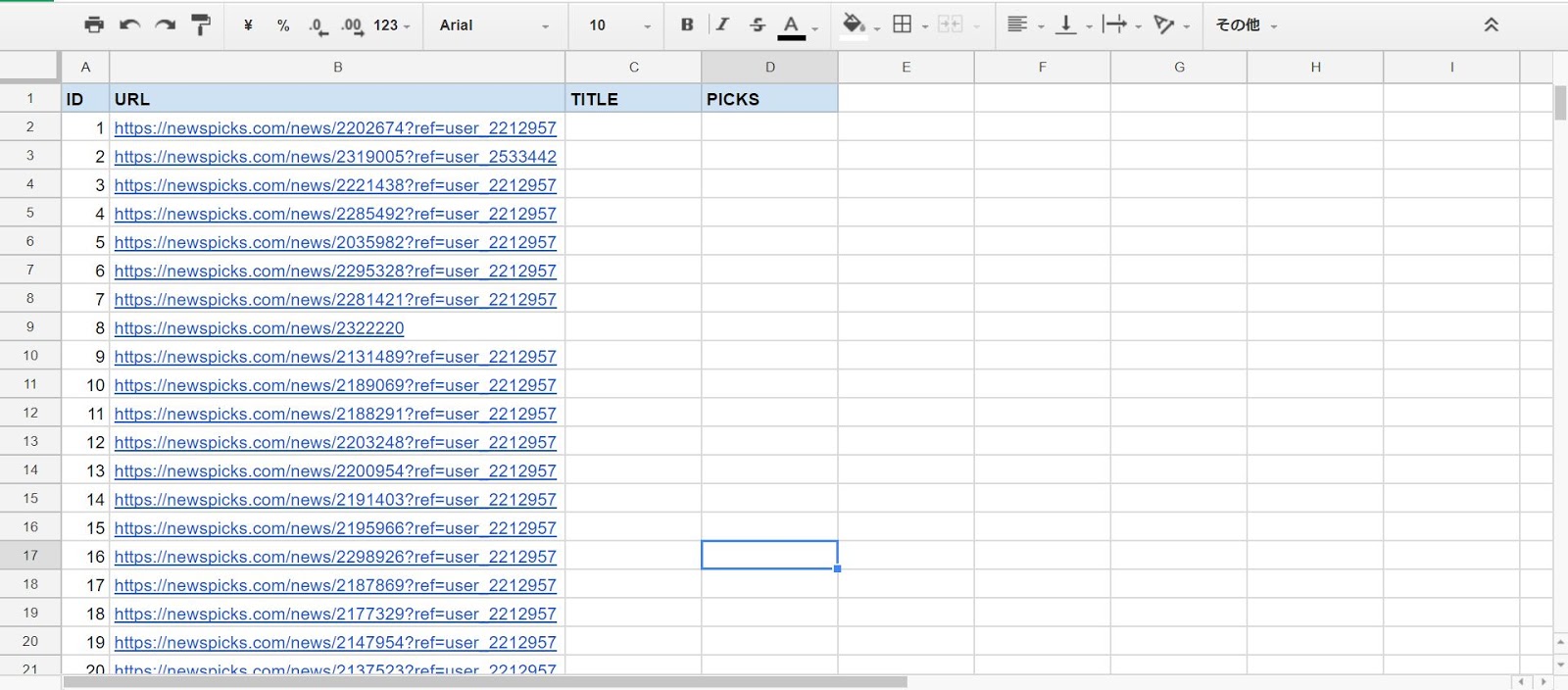
あとは、データを取り出したい情報を集めます。僕の場合は、自分がNews Picksにアップロードした記事が何ピックされたか調べたいので、今回は自分のNews Picksの記事のURLを準備しました。
データを取りたいURLをスプレッドシートに乗せる
データを取りたいURLを列挙します。
下の画像みたいな感じです。
(WINDOWS)取得したいページでF12を押して、入手したい情報を検索する
今度は自分の取得したい情報が存在するページを開きます。そしてF12ボタンを押すと、自なにやら小難しそうな画面が出てきます。右側のコードが書いてあるページをクリックして、ctrf + fを押してキーワードを検索します。
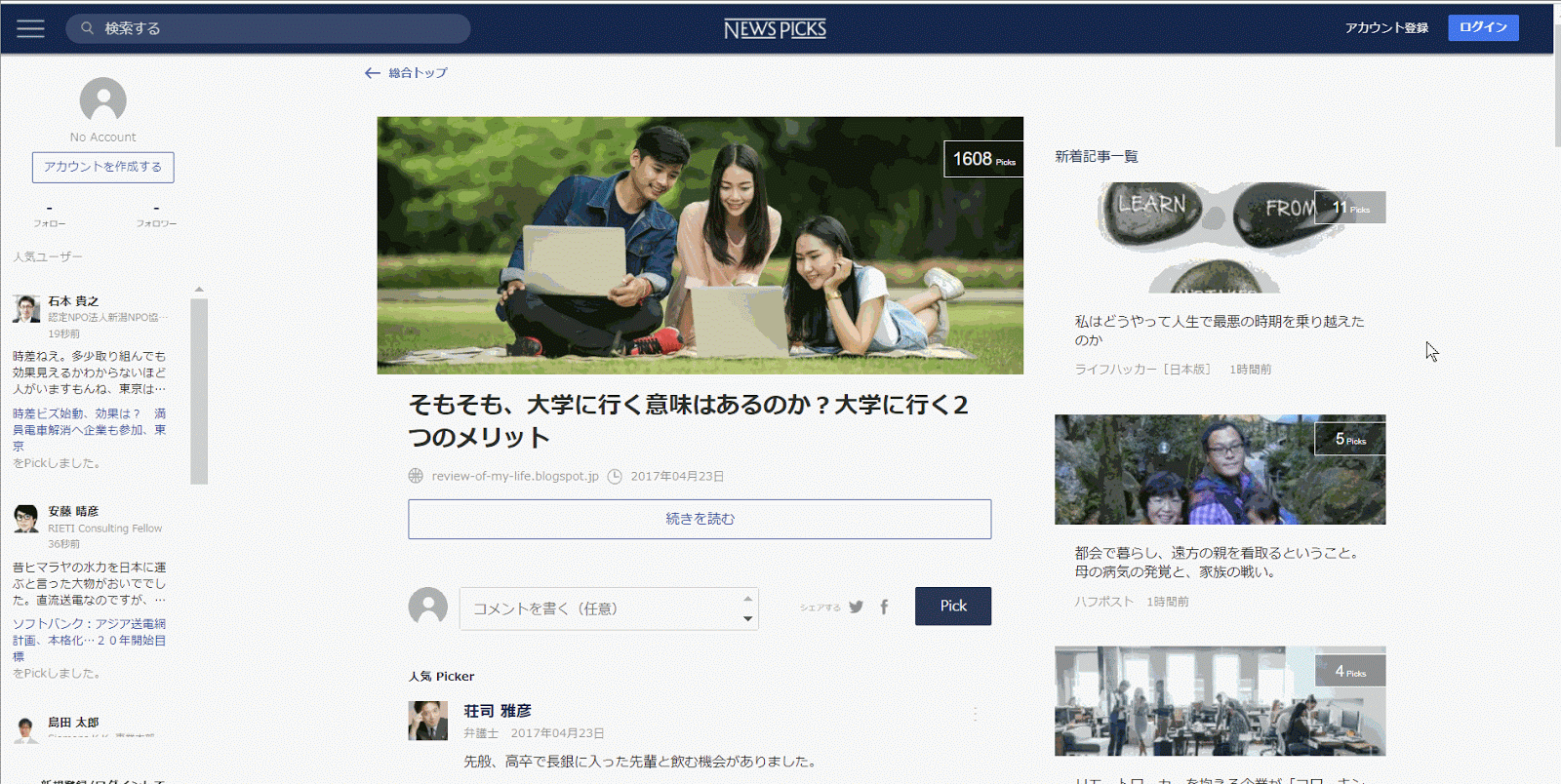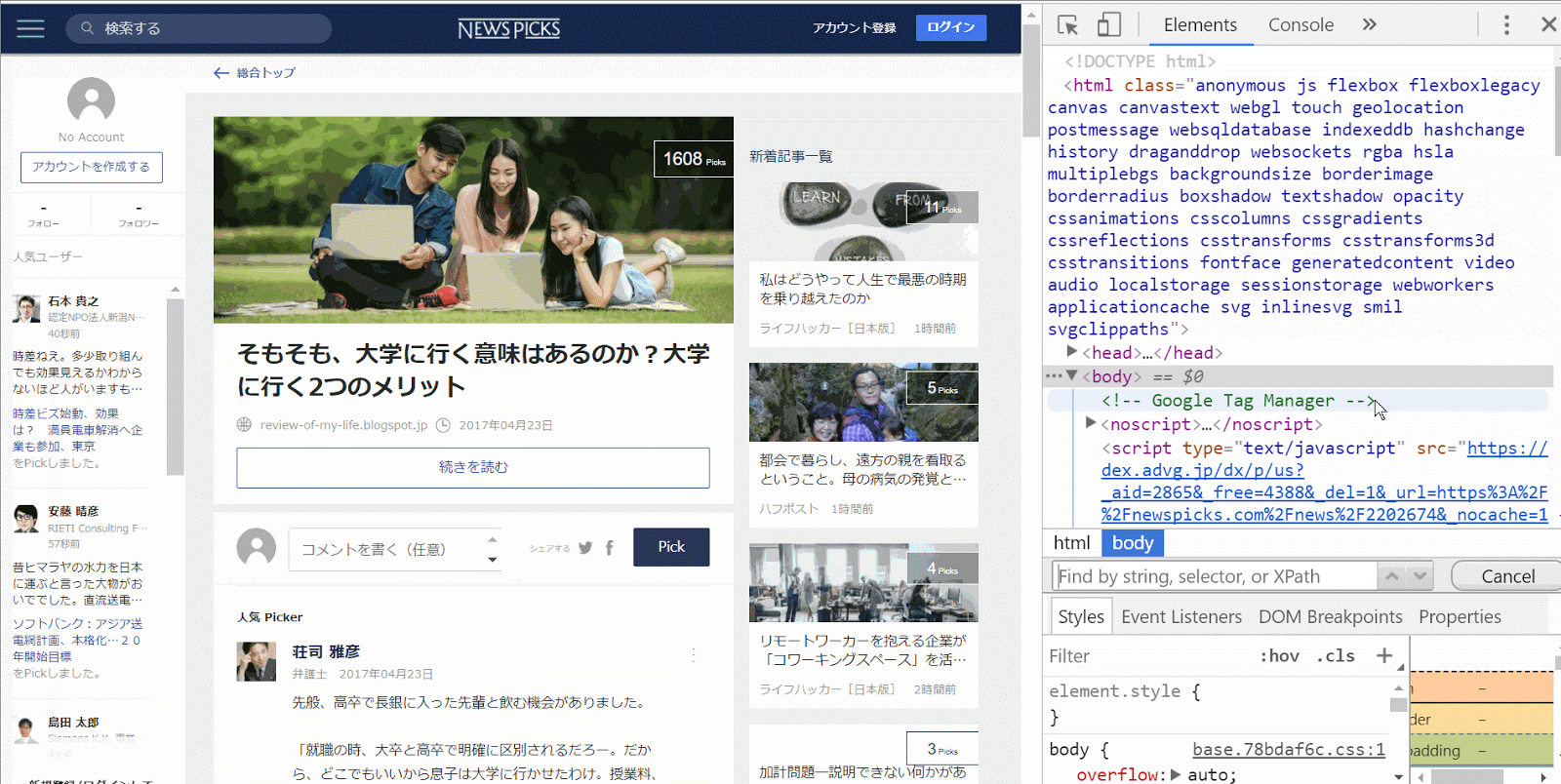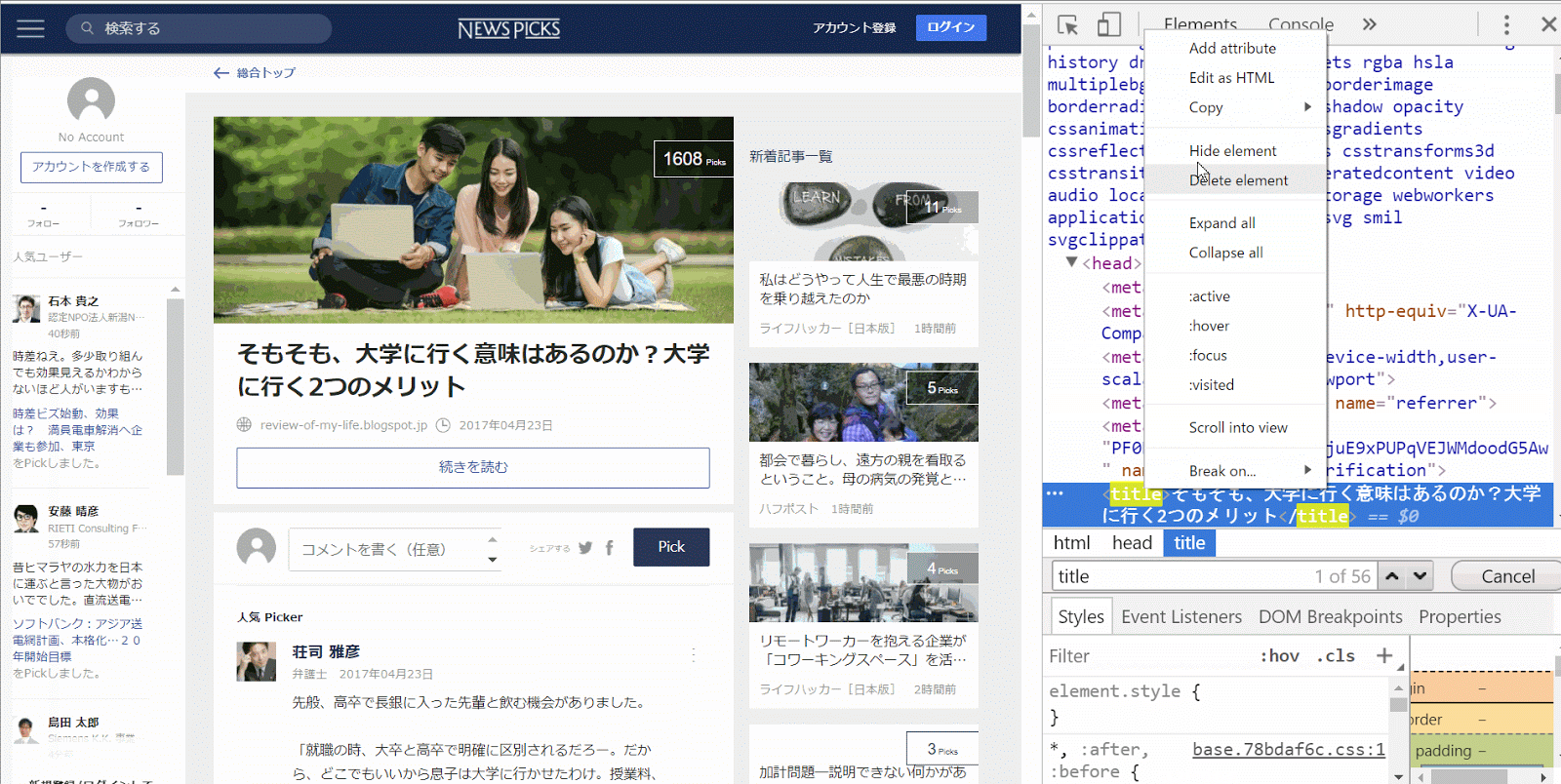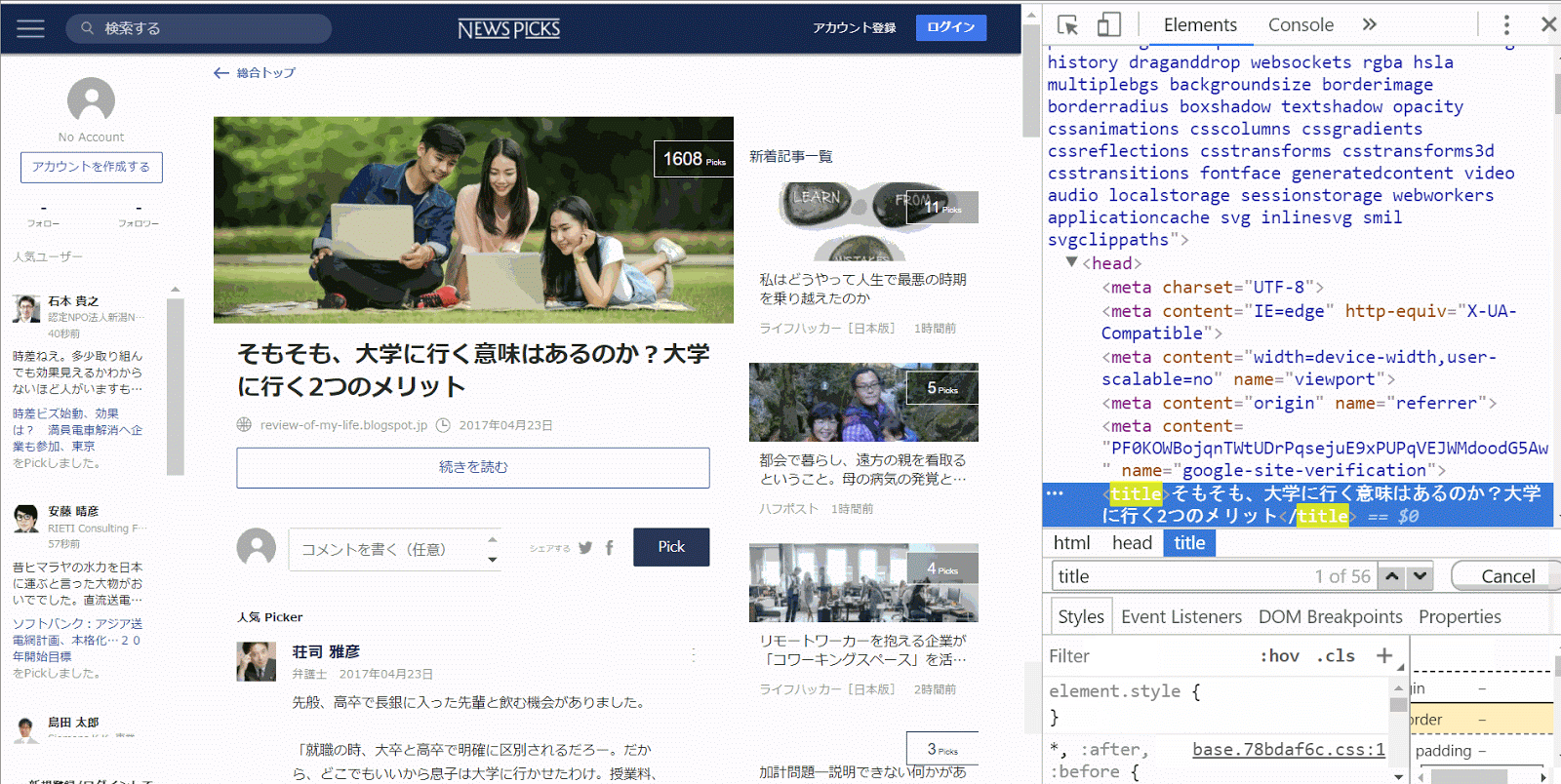
僕の場合はtitleがほしかったので、titleと検索するとタイトルが入っている部分のコードが見つかります。
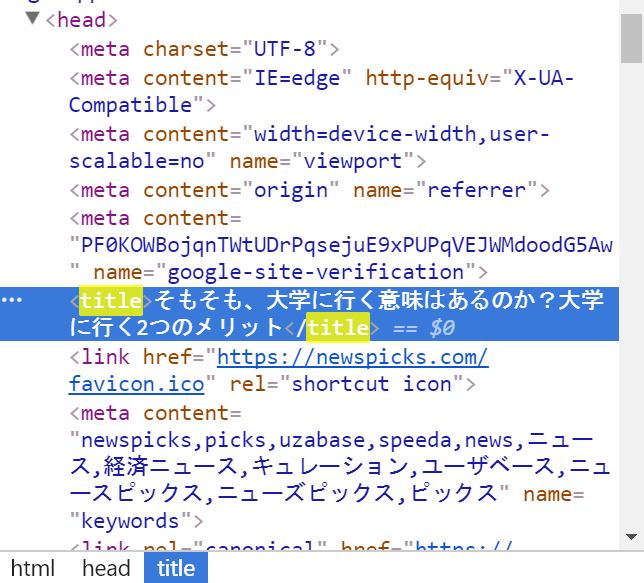
このtitleというところを右クリックすると、
Copy > Copy Xpathをクリックします。これを押すと、この情報が存在する住所データがクリップボードに保存されます。これで、準備完了です。
GOOGLE SPREADSHEETで、IMPORTXML関数を利用する
あとは、SPREADSHEETにIMPORTXML関数を使ってやれば、簡単にデータをスクレイピング可能です。セルにIMPORTXML(URLが存在するセル、Xpath)と指定してあげればできます。
僕の取得したTITLEの場合はこうです。
=IMPORTXML(B2,"/html/head/title")
これで入力を終えると、自動でデータを取得してくれます。
下までだだだーと伸ばしていくと・・・・

全部タイトルが取得できました!やったね!
PICK数も取得してみた
どうせならタイトルとピック数を見てみたいですね。今度はPicks数を探します。
この1608 picksという数字がとりたいです

このピック数、すべての記事でとってみましょうか。
さっきみたいな感じでとります。
ctrl + fで検索すると、その住所データが出てきます。

これを右クリックして、Copy > Copy Xpathを取得します。
あとは全く同じようにやってみます。
=IMPORTXML(B2,"/html/body/div[2]/div[2]/div[2]/div/div[1]/div[3]")そうすると全部のピック数を取得してくれます。もちろんスプレッドシートもエクセルと同じように使えるので、フィルタを使って並び替えたりもできます。

自分で更新しなくても、SPREADHSHEETを開くたびにスクレイピングしてくれます。
プログラミングを覚えなくても、全然できるので重宝します。
プログラミングを書かずにスクレイピングをするなら Octoparse
公式サイト:https://www.octoparse.jp/
【Octoparse】コードを書かずに今すぐスクレイピングをしたい方必見!
簡単3分!無料でデータ取得の業務自動化が可能。プログラミング未経験者でもWebスクレイピングをしたいなら。
『Octoparse』は、無料かつプログラミング不要のWebスクレイピングツールです!

DAI
これまでプログラミング未経験者であれば、数十時間かけて勉強しなければできなかったスクレイピング作業を、登録からインストールまでたったの3分程度でできてしまうツールになっています。
「Octoparse」のいいところは、数えたらきりがないのですが、絞ると以下の3点です!
- 無料版できることがかなり多い。
- プログラミング経験が全くない人でも、データの取得を自動化できる。
無料版できることがかなり多い。
Octoparseは、無料版でも以下のようなデータを簡単に取得することができます。
- ECサイトの検索結果や、商品詳細などのデータ
- メディアやニュースサイトなどの記事データ
- SNSの投稿データ
DAI
例としては、YouTubeから特定のキーワードで検索した際の動画URLを取得したり、Indeedなどの求人サイトから給与の情報を取得したりするなどがあります。
有料版と無料版の違いは、いくつかありますが代表的なものは以下の2つです。
- タスクの定期実行ができない。
- APIを使うことができない。
DAI
ですが、正直個人で利用する分には、有料の機能はそこまで必要にならないと思うので、無料版でやれることが多く、ほんとに無料でいいのか…というレベルでした。
プログラミング経験が全くない人でも、データの取得を自動化できる。
また、Octoparseを利用する一番のメリットは、プログラミング経験が全くない人でもスクレイピングをして、データ取得を自動化できるということです。
通常、プログラミング完全未経験の方がスクレイピングをしようとすると、以下のような課題に直面します。
- HTML、CSS、JavaScript、Pythonなど、複数の言語を学習しなければならない。
- PC上で環境構築などをしなければならない。
- 定期実行をしたい場合は、仮想サーバーなどの知識もつける必要がある。
そもそも、自分でやってみたもののエラーがでてほしいデータが取得できないなどの事態に陥る場合もあり、結局時間をかなり浪費してしまう…ということもあり得ます。
DAI
その点、Octoparseは画面をクリックするだけでスクレイピングを行うことができるので、ちょっとスクレイピングをしてみたい!という方でも時間を浪費することなく試すことができます。
※有料版を使えば、データ取得の定期実行なども可能なため、プログラミングを学習しなければできなかったことの多くをOctoparseを使えばクリックだけで置き換えることが可能になります。
DAI
登録から体験まで3分程度でできるので、ちょっとスクレイピングを試してみたい!という方にはかなりおすすめできます。
【Octoparse】コードを書かずに今すぐスクレイピングをしたい方必見!
簡単3分!無料でデータ取得の業務自動化が可能。プログラミング未経験者でもWebスクレイピングをしたいなら。



